Keycloak Admin REST API performance limitations
Previously, we have dealt with some limitations related to Keycloak that might be useful to know before actively using Keycloak Admin REST API in your projects. These are the following:
- we do not have performance guarantees for non-OIDC-related endpoints. Yes, there are special benchmark tests maintained by the Keycloak team, but nevertheless, standard OIDC endpoints are the main focus here.
- if you create custom attributes for users in Keycloak and then try to work with them over Admin REST API you can be unpleasantly surprised that database schema doesn’t have needed optimizations that allow you to handle these requests with a good SQL execution plan (this is what this story is about)
The problem with Keycloak Admin REST API can be mitigated from an architectural perspective by just replacing local Keycloak users with a user storage SPI, so indirect management of users in Keycloak through the 3-rd party API instead of Admin REST API could be a good idea for you as long as Keycloak User Storage SPI are supported.
Let’s begin.
Keycloak’s JPA related Java code related to search by attribute name and value using Admin REST API is transformed by Hibernate ORM into SQL that uses the lower() function, which prevents the use of indexes in cases of searching for users by custom attributes. Thus, the following request created to search a user by its custom client_id attribute:
curl --location 'http://keycloak-fqdn/auth/admin/realms/<realm-name>/users?q=client_id%3A3a79f454-1573-4613-9550-a279e762829b' \
--header 'Authorization: ******'
which is handled by Keycloak code, will be transformed by Hibernate ORM to SQL like this (before git commit discussed later)
select userentity0_.ID as id1_72_, userentity0_.CREATED_TIMESTAMP as created_2_72_, userentity0_.EMAIL as email3_72_, userentity0_.EMAIL_CONSTRAINT as email_co4_72_, userentity0_.EMAIL_VERIFIED as email_ve5_72_, userentity0_.ENABLED as enabled6_72_, userentity0_.FEDERATION_LINK as federati7_72_, userentity0_.FIRST_NAME as first_na8_72_, userentity0_.LAST_NAME as last_nam9_72_, userentity0_.NOT_BEFORE as not_bef10_72_, userentity0_.REALM_ID as realm_i11_72_, userentity0_.SERVICE_ACCOUNT_CLIENT_LINK as service12_72_, userentity0_.USERNAME as usernam13_72_ from USER_ENTITY userentity0_ left outer join USER_ATTRIBUTE attributes1_ on userentity0_.ID=attributes1_.USER_ID where userentity0_.REALM_ID=$1 and lower(attributes1_.NAME)=$2 and lower(attributes1_.VALUE)=$3 order by userentity0_.USERNAME asc limit $4
where these lower() functions
lower(attributes1_.NAME)=$2 and lower(attributes1_.VALUE)=$3
prevent the RDBMS from using indexes, causing the SQL query execution plan to include a full sequence scan or a parallel sequence scan of the table.

A parallel sequential scan in PostgreSQL means that a full table scan is performed by multiple worker processes, with each worker assigned a different portion of the table to process independently.
Of course, this leads to busy PostgreSQL worker processes performing numerous machine operations to compare strings (bytes). As a result, the workers cannot handle other useful tasks, such as executing additional SQL queries.
Fix index-related performance problem
Thankfully, PostgreSQL provides a workaround by allowing the use of special composite indexes with the lower() function in their definitions, enabling us to mitigate this issue (unfortunately, I don’t know how things work with another RDBMS):
CREATE INDEX concurrently idx_attr_lower_user_attribute_name_value ON user_attribute(lower(name), lower(value));
ANALYSE user_attribute;
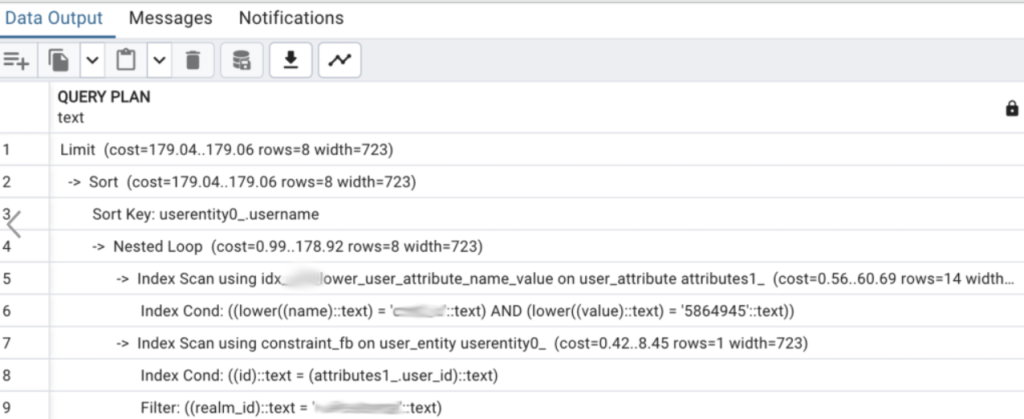
With this index in place, our execution plan looks good as shown above. But some time ago, we got these changes in Keycloak:
https://github.com/keycloak/keycloak/commit/05425549844f8e222b62ee01de1bd5c69b64c9ca
and after these changes, created earlier composite index with the two lowered fields stopped working effectively, and of course, we got high CPU consumption in PostgreSQL.
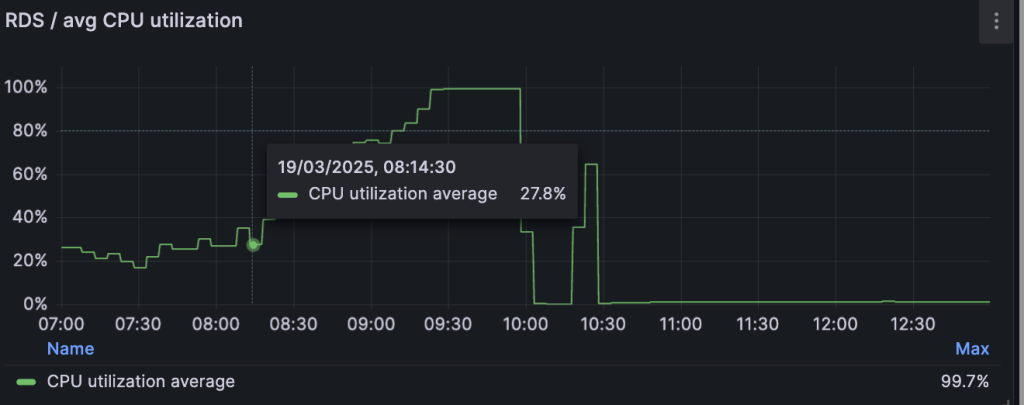
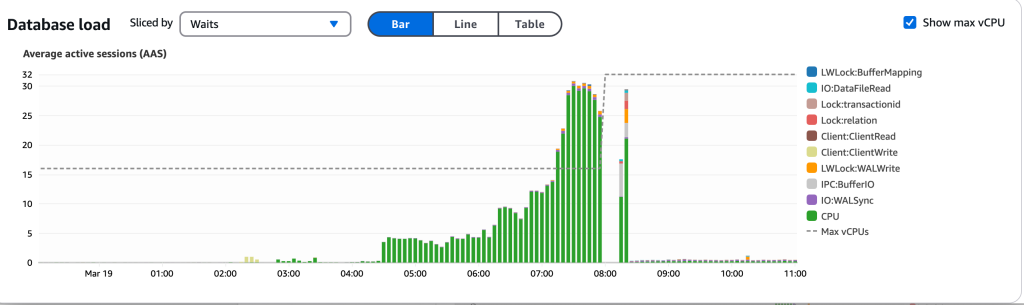
We could observe busy workers waiting for the completion of CPU-intensive SQL queries in performance insights:
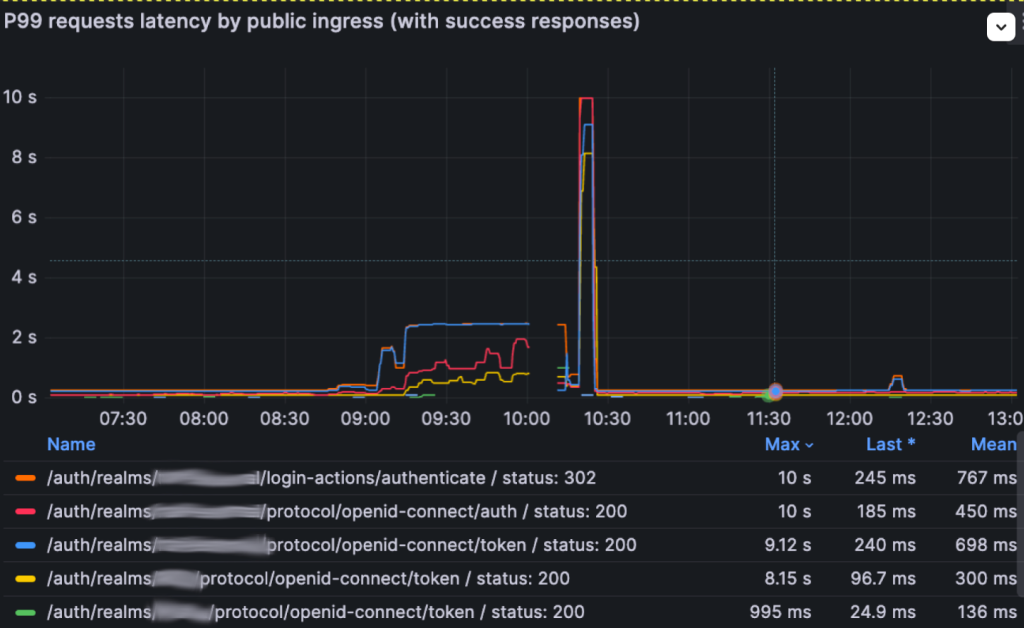
and of course, our latency was far away from our SLOs:
To fix this just do these steps:
- delete the previous custom index if you have
- create a new index as shown below only with one lower on user_attribute.value field
CREATE INDEX idx_name_lower_user_attribute_value ON user_attribute(lower(value));
In the screenshots provided below, you can see the execution plan before and after the index creation.
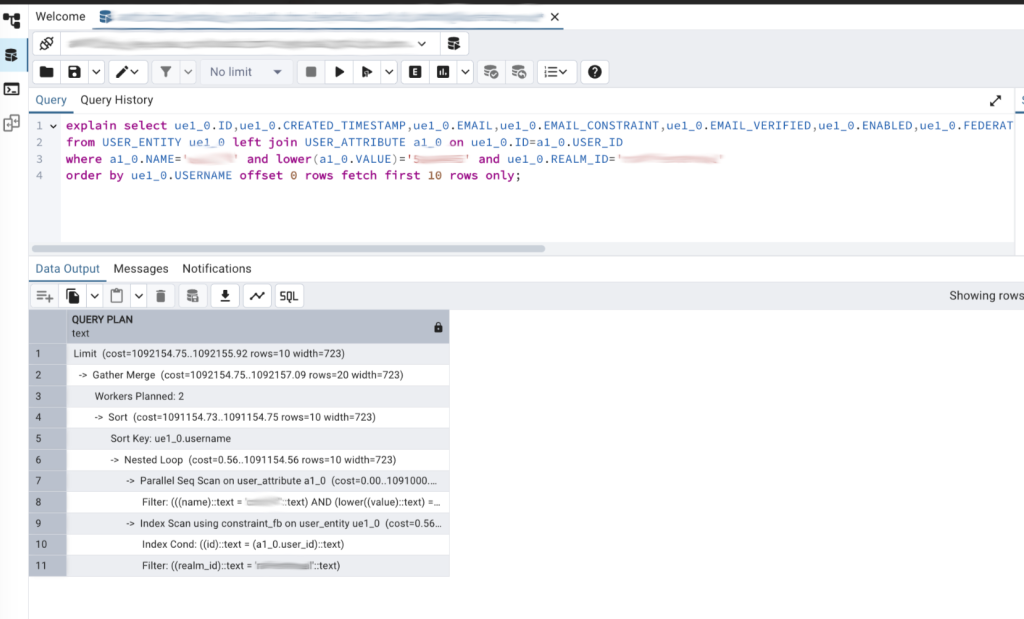
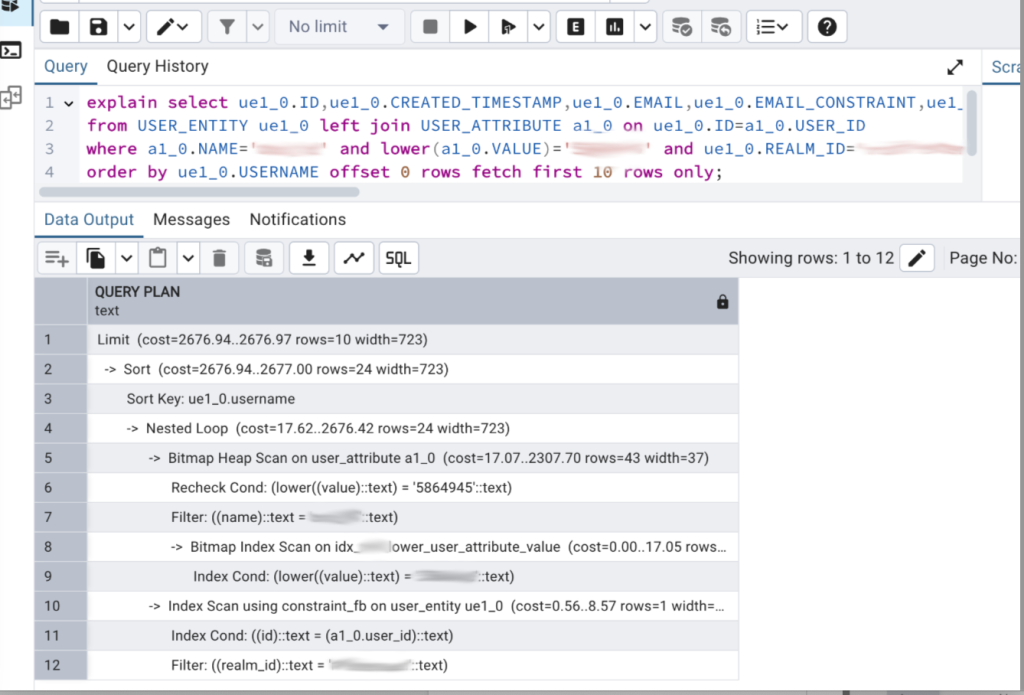
Consequences
Having benchmark testing in place will help you detect issues before going to production, so don’t ignore them. If you are going to use something other than PostgreSQL RDBMS, consider how it will work in your case.
Keycloak maintainers improve Admin REST API performance step by step, and maybe we will not need to create our custom indexes in the future.